TL;DR
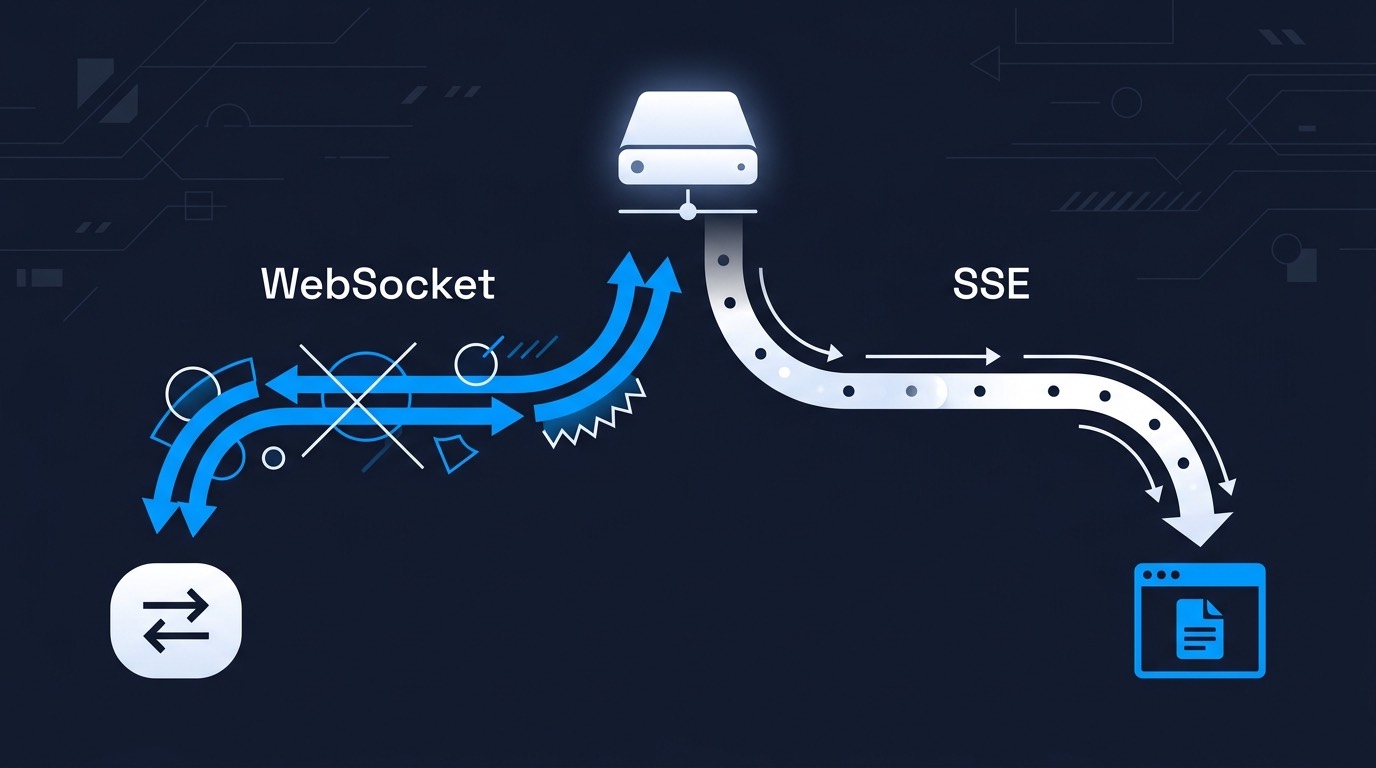
WebSocket is powerful but operationally heavy. When your data flow is mostly the server talking and the client listening — a progress bar, a live dashboard, or a notification feed — you almost certainly don't need it. Server-Sent Events (SSE) handles that workload over standard HTTP, with native reconnection, no state management overhead, and zero infrastructure disruption. The rule is simple: match the transport to the shape of the problem.
Every time a real-time requirement lands on the table, something almost Pavlovian happens: "Let's spin up a WebSocket server." No one questions it. It feels like the obvious move.
I ran into this exact situation while building an internal tool (let's call it Devora) that fetches data from an external server. The backend kicks off a long-running fetch across hundreds or thousands of records and needs to reflect progress live in the UI — how many records have been processed, which ones hit errors, and what the error was. During planning, the first instinct on the table was WebSocket. The argument was straightforward: we need real-time updates, so we need WebSocket.
It wasn't the right call. And the conversation that followed is exactly what this article is about.
WebSocket is a brilliant piece of engineering built for a specific class of problems. The industry habit of reaching for it first, regardless of what the problem actually is, is where things go wrong. It's not that the technology is bad — it's that it carries real operational weight, and most of the time the problem is light.
Read the problem before picking the tool
Before choosing any transport protocol, one question is worth asking honestly: does the client actually need to talk back to the server in real time, or does it just need to listen?
That distinction matters more than most teams realize. If the answer is mostly "listen" — the server pushes data, the client renders it, and the user interacts through normal clicks and form submissions — then you're describing an asymmetric data flow that does not require a bidirectional pipe.
WebSocket gives you a bidirectional pipe. That's its whole value. But a pipe you only ever use in one direction isn't a feature — it's overhead you're now responsible for managing.
What WebSocket actually does to your stack
WebSocket doesn't extend HTTP — it escapes it. The connection starts as a normal HTTP request with an Upgrade: websocket header, but once the handshake completes, HTTP is abandoned entirely. What you're left with is a raw, full-duplex TCP connection that your existing infrastructure doesn't know how to treat.
At the protocol layer: your reverse proxy, API gateway, auth middleware, rate limiter, and logging pipeline are all built around the HTTP request/response lifecycle. A WebSocket connection bypasses that lifecycle. You don't lose those capabilities, you just have to rebuild them from scratch inside custom frame handlers. That's non-trivial work and ongoing maintenance.
At scale: WebSocket connections are stateful. Each open connection pins a client to a specific server instance and holds memory on that node for its entire duration. Horizontal scaling becomes fragile — you can't rebalance connections without forcing a wave of simultaneous reconnects. Connection draining during deployments needs careful orchestration. Your load balancer needs sticky sessions.
For a collaborative whiteboard or a multiplayer game where the client is continuously streaming inputs at high frequency, WebSocket earns that complexity. For a progress bar reflecting a long-running fetch, it doesn't.
A practical decision matrix
Before going deeper, this table captures when each transport genuinely fits. Use it as a quick sanity check at the start of any architecture conversation:
The lighter option — and why it works
Server-Sent Events take the opposite approach: instead of abandoning HTTP, they embrace it. The client opens a normal HTTP request. The server responds with a Content-Type: text/event-stream header and keeps the response body open, trickling data down as plain text whenever there's something to send. That's it.
To your load balancer, firewall, and CDN, it looks exactly like a slow HTTP response — that's exactly what it is. Your existing auth pipeline, logging, rate limiting, and stateless horizontal scaling all continue to work without modification.
Going back to the Devora tool: the backend streams a progress event for each record fetched from the remote server — including the record ID and any error encountered — and the frontend updates the UI live as events arrive. Here's what the implementation actually looks like:
// Client Side (browser)
const stream = new EventSource('/api/fetch-progress');
stream.onmessage = (event) => {
const { fetched, total, record, error } = JSON.parse(event.data);
updateProgressBar(fetched, total);
if (error) {
appendIssue(record, error); // surface per-record errors live
} else {
markRecordDone(record);
}
};
stream.onerror = () => {
// Browser auto-reconnects — no extra code needed
};
// Server — Node.js / Express
app.get('/api/fetch-progress', async (req, res) => {
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
const records = await getRecordList(); // list from remote server
for (const record of records) {
const result = await fetchFromRemote(record.id);
res.write(`data: ${JSON.stringify({
fetched : records.indexOf(record) + 1,
total : records.length,
record : record.id,
error : result.error ?? null,
})}\n\n`);
}
res.end();
});No heartbeat logic, no reconnection handling, no custom frame parsing. The browser's EventSource API takes care of reconnection automatically. If the network drops mid-fetch, the client reconnects and the server can resume from the last acknowledged event using the Last-Event-ID header — no custom sync handshake required.
One constraint worth stating clearly
SSE is text-only. The protocol is UTF-8 by spec, which means binary data — images, audio blobs, raw byte buffers — can't be streamed directly. If you need to push binary payloads in real time while the client simultaneously sends data back continuously, that's the point where WebSocket starts earning its complexity. For the vast majority of real-time UI scenarios — status events, metrics, progress states, LLM token streams — this is a non-issue.
On authentication: the browser's EventSource API doesn't support custom headers, so passing a bearer token the way you would in a WebSocket upgrade request isn't possible. In practice, this resolves cleanly in two ways: cookie-based auth if your SSE endpoint is on the same domain (the browser sends the cookie automatically), or a short-lived query-parameter token for cross-origin setups. Neither is a reason to reach for WebSocket; it's just something to plan for upfront.
Two objections that used to be valid
"SSE breaks under the browser's six-connection limit." This was real under HTTP/1.1, where browsers capped concurrent connections per domain at six. An SSE stream that never closes would permanently occupy one of those slots. The modern web runs on HTTP/2 and HTTP/3, where multiplexing means a single TCP connection carries hundreds of virtual streams. Your API calls, static assets, and SSE stream all share the same pipe. The slot problem is dead.
"SSE is a niche, forgotten feature." The typing effect in every LLM chat interface — tokens appearing word by word as the model generates them — is SSE. Every major AI SDK defaulted to SSE for streaming because it pushes text natively, scales over standard serverless infrastructure, and doesn't require a socket cluster to serve millions of concurrent sessions. SSE went from obscure browser API to the backbone of the most-used AI products in the world.
The operational cost gap
At 50,000 concurrent users, a WebSocket deployment holds 50,000 live memory states across stateful nodes that can't be freely swapped or scaled horizontally without careful orchestration. The same workload over SSE runs on stateless HTTP — standard horizontal scaling, CDN-friendly delivery, no connection affinity. For most SaaS workloads, that translates to a meaningfully lower infrastructure bill and a quieter on-call rotation.
The same principle holds for video
Teams building live video features fall into the same trap — reaching for stateful streaming protocols when the media industry solved this years ago with HTTP Live Streaming (HLS). HLS doesn't maintain an open media pipe. It breaks the video stream into small, standard HTTP file segments and delivers them via a plain text playlist index. The player fetches segments sequentially over regular HTTP, the same way it fetches any static file.

Because those segments are standard HTTP responses, a global CDN can cache and deliver them to millions of concurrent viewers without additional compute on your origin. That's something a stateful pipe can never offer.
HLS trades connection persistence for HTTP cacheability — every segment is a plain HTTP request, which means CDN edges handle the scale, not your origin server.
Where WebSocket belongs? and what's coming next?
None of this is an argument against WebSocket. It's an argument for using it when the problem actually fits. If you're building a collaborative editor where multiple users edit the same document simultaneously and every keystroke from every participant needs to propagate to every other client in under 100 milliseconds, you need WebSocket. If you're building a multiplayer browser game where the client streams input events at 60fps while consuming peer state updates, you need WebSocket.
For backend-to-backend or mobile-to-backend scenarios, gRPC bidirectional streaming is worth considering — it offers similar real-time capabilities over HTTP/2 with strong typing and better tooling for service-to-service communication. WebTransport over QUIC is also worth watching for future browser-based use cases, offering lower latency than TCP-based WebSocket while staying closer to the web platform. Neither changes the calculus for today's typical server-push UI workload, but they're worth knowing about.
The question that ends the debate
The conversation I described at the start didn't end with a technical argument. It ended with a question: what are we actually trying to do here?
Reflect progress from a long-running backend fetch to a UI showing how many records were processed, which ones hit errors, and what those errors were. One-way data. The server knows things; the client needs to see them. No continuous client input, no binary payload, no sub-50ms latency requirement. The problem was simple. The solution should have been simple from the first minute of the planning session.
WebSocket is not a safe default — it's a deliberate choice that comes with real operational costs. SSE is not a workaround — it's the right tool for a specific and very common class of problems. The same principle — choose by context, not by trend — applies across every frontend architecture decision. The difference between shipping a stable system in a day and spending two weeks wrestling with socket cluster orchestration often comes down to asking one honest question early: does the client actually need to talk back to the server in real time, or does it just need to listen?
“Not every trend is a solution. Think before you follow.”
